
Speed up requests: Asyncio for Requests in Python
by Connie Xu
Connie Xu is currently studying Computer Science at Princeton University, where she has sharpened her skills in Algorithms and Data Structures as well as Linear Algebra. She is interested in learning more about Natural Language Processing and Machine Learning applications. In her free time, she watches cooking videos or practices beatboxing. Connie was one of NLMatics’ 2020 summer interns.
Speed up requests: Asyncio for Requests in Python
Don’t be like this.

As you have probably already noticed because you decided to visit this page, requests can take forever to run, so here’s a nice blog written while I was an intern at NLMatics to show you how to use asyncio to speed them up.
What is asyncio?
It is a Python library that uses the async/await syntax to make code run asynchronously.
What does it mean to run asynchronously?
Synchronous (normal) vs. Asynchronous (using asyncio)
- Synchronous: you must wait for the completion of the first task before starting another task.
- Asynchronous: you can start another task before the completion of the first task.


For more information on the distinction between concurrency, parallelism, threads, sync, and async, check out this Medium article.
Simple analogies
Brick and Mortar

Simon and Ash are building 5 walls of brick.
- Simon builds one wall and waits for it to set before starting to build the next wall (synchronous).
- Ash, on the other hand, starts building the next wall before the first one sets (asynchronous).
</br> Ash starts the next task whereas Simon waits, so Ash (asynchronous) will finish faster. The lack of waiting is the key to why asynchronous programming provides a performance boost.
A good coding use case would be when you have a lot of time-consuming requests lined up with the outputs independent of each other. request1 takes a while to finish running, so instead of waiting, you start request2, which doesn’t affect the output of request1.
Laundry

Be wary that an asynchronous approach does not provide any performance boost when all the tasks are dependent on each other. For example, if you are washing and drying clothes, you must wait for the clothes to finish washing first before drying them no matter what, because drying clothes is dependent on the output of the washing. There is no use in using an asynchronous approach, because the pipeline is just the same as a synchronous approach.
The coding equivalent of this laundry example is when the output of request1 is used as the input in the request2.
For a further look into when and when not to use asynchronous programming, check out this Stackify thread.
What syntax do I need to know?
| Syntax | Description | Example |
|---|---|---|
| async | Used to indicate which methods are going to be run asynchronously <p> → These new methods are called coroutines. |
 |
| await | Used to run a coroutine once an asynchronous event loop has already started running → await can only be used inside a coroutine → Coroutines must be called with await, otherwise there will be a RuntimeWarning about enabling tracemalloc. </br> |
 |
| asyncio.run() | Used to start running an asynchronous event loop from a normal program → asyncio.run() cannot be called in a nested fashion. You have to use await instead. → asyncio.run() cannot be used if you are running the Python file in a Jupyter Notebook because Jupyter Notebook already has a running asynchronous event loop. You have to use await. (More on this in the Running the Code section) |
 |
| asyncio.create_task() | Used to schedule a coroutine execution → Does not need to be awaited → Allows you to line things up without actually running them first. |
 |
| asyncio.gather() | Used to run the scheduled executions → Needs to be awaited → This is vital to the asynchronous program, because you let it know which is the next task it can pick up before finishing the previous one. |
 |
If you are thirsting for more in-depth knowledge on asyncio, check out these links:
But with that, let’s jump straight into the code.
Follow along with the Python file and Jupyter Notebook in this github repo that I developed for this post!
Code
Preliminary
Get imports and generate the list of urls to get requests from. Here, I use this placeholder url. Don’t forget to do pip install -r requirements.txt in the terminal for all the modules that you don’t have. Normal requests cannot be awaited, so you will need to import requests_async to run the asynchronous code.
import requests, requests_async, asyncio, time
itr = 200
tag = 'https://jsonplaceholder.typicode.com/todos/'
urls = []
for i in range(1, itr):
urls.append(tag + str(i))
Synchronous
This is what some typical Python code for requests would look like.
def synchronous(urls):
for url in urls:
r = requests.get(url)
print(r.json())
Asynchronous
Incorrect Alteration
The following is an understandable but bad alteration to the synchronous code. The runtime for this is the same as the runtime for the synchronous method, because you have not created a list of tasks that the program knows it needs to execute together, thus you essentially still have synchronous code.
async def asynchronous_fail(urls):
for url in urls:
r = await requests_async.get(url)
print(r.json())
Correct Alteration
Create a list of tasks, and run all of them together using asyncio.gather().
async def asynchronous(urls):
tasks = []
for url in urls:
task = asyncio.create_task(requests_async.get(url))
tasks.append(task)
responses = await asyncio.gather(*tasks)
for response in responses:
print(response.json())
Running the Code
Python
Simply add these three lines to the bottom of your Python file and run it.
starttime = time.time()
asyncio.run(asynchronous(urls))
print(time.time() - starttime)
If you try to run this same code in Jupyter Notebook, you will get this error:
RuntimeError: asyncio.run() cannot be called from a running event loop
This happens because Jupyter is already running an event loop. More info here. You need to use the following:
Jupyter Notebook
starttime = time.time()
await asynchronous(urls)
print(time.time() - starttime)
Ordering
Asynchronous running can cause your responses to be out of order. If this is an issue, create your own responses list and fill it up, rather than receiving the output from asyncio.gather().
async def asynchronous_ordered(urls):
responses = [None] * len(urls) # create own responses list
tasks = []
for i in range(len(urls)):
url = urls[i]
task = asyncio.create_task(fetch(url, responses, i))
tasks.append(task)
await asyncio.gather(*tasks) # responses is not set to equal this
for response in responses:
print(response.json())
async def fetch(url, responses, i):
response = await requests.get(url)
responses[i] = response # fill up responses list
Batching
Sometimes running too many requests concurrently can cause timeout errors in your resource. This is when you need to create tasks in batches and gather them separately to avoid the issue. Find the batch_size that best fits your code by experimenting with a smaller portion of requests. Requests that take longer to process (long server delay) are more likely to cause errors than others. In my own experience with NLMatic’s engine, MongoDB had timeout errors whenever I ran batches of size greater than 10.
async def asynchronous_ordered_batched(urls, batch_size=10):
responses = [None] * len(urls)
kiterations = int(len(urls) / batch_size) + 1
for k in range(0, kiterations):
tasks = []
m = min((k + 1) * batch_size, len(urls))
for i in range(k * batch_size, m):
url = urls[i]
task = asyncio.create_task(fetch(url, responses, i))
tasks.append(task)
await asyncio.gather(*tasks)
for response in responses:
print(response.json())
Runtime Results

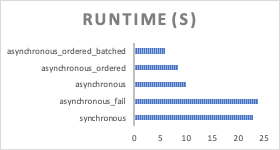
synchronous and asynchronous_fail have similar runtimes because the asynchronous_fail method was not implemented correctly and is in reality synchronous code.
asynchronous, asynchronous_ordered, and asynchronous_ordered_batched have noticeably better runtimes in comparison to synchronous - up to 4 times as fast.
In general, asynchronous_ordered_batched gives fast and stable code, so use that if you are going for consistency. However, the runtimes of asynchronous and asynchronous_ordered can sometimes be better than asynchronous_ordered_batched, depending on your database and servers. So, I recommend using asynchronous first and then adding extra things (order and batch) as necessary.
Summary
As you have seen, asyncio is a helpful tool that can greatly boost your runtime if you are running a lot of independent API requests. It’s also very easy to implement when compared to threading, so definitely try it out. Of course, make sure that your requests are independent.
Now I must conclude by saying that using asyncio improperly implemented can cause many bugs, so sometimes it is not worth the hassle. If you really must, use my guide and use it s p a r i n g l y.
And that’s a wrap!