
Smooth Inverse Frequency (SIF) Embeddings in Golang
by Daniel Ye
Daniel Ye is a junior at Cornell University majoring in Computer Science and minoring in Operations Research and Information Engineering. He is interested in machine learning, natural language processing, and data science. He has worked on projects involving manufacturing data collection/analysis, greenhouse environmental regulation, and a multiplayer programming game. In his free time he enjoys playing tennis, running, hiking, and playing cello or guitar. Daniel was one of NLMatics’ 2020 summer interns.
Smooth Inverse Frequency (SIF) Embeddings in Golang
Daniel Ye
Table of Contents
I am a rising junior majoring in computer science and minoring in operations research and information engineering at Cornell Engineering. This summer, I interned at NLMatics, and one of the projects I worked on was implementing a Smooth Inverse Frequency model using Golang. This is able to calculate sentence embeddings from sequences of words in the form of vectors, which mathematically represent the meaning of the sentence. We use it to encode documents and queries into embeddings which are then processed further using other natural language processing models to get search results. However, our original Python implementation was fairly slow at calculating these embeddings, and it scaled poorly with increasing document sizes or concurrent requests, so we needed to find a way to speed up the service.
Over the course of about four weeks, I worked on combating this issue by developing a Golang implementation of the model and switching from HTTP 1.0 protocol to gRPC protocol for the server. This increased the amount of concurrent processing we were able to utilize, and reduced overhead for connecting and sending requests to the server, speeding up the service greatly. Ultimately, I was able to build a system that generated more accurate sentence embeddings at much faster speeds.
Word embeddings are one of the most important developments in the field of modern Natural Language Processing. Translating the meaning behind words and the semantic relationships between them into measurable quantities is a crucial step in processing language. Many words, such as “cat” and “dog” or “Mozart” and “Beethoven” have almost no physical characteristics that would reveal their similarities. Instead, modern algorithms like Google’s Word2Vec developed in 2013 or Stanford’s GloVe essentially count the cooccurrences of words with other words, and condense these values into dense, relatively low-dimensional vectors. Their models train on massive corpora of English text such as all of Wikipedia, and embed words as vectors based on which other words they appear in proximity to. So, if “cat” and “dog” are found together in many sentences or documents, they will have very similar vector values. This method is able to capture not only semantic similarity, but also analogies (woman is to man as king is to __) and the effects of prefixes or suffixes.
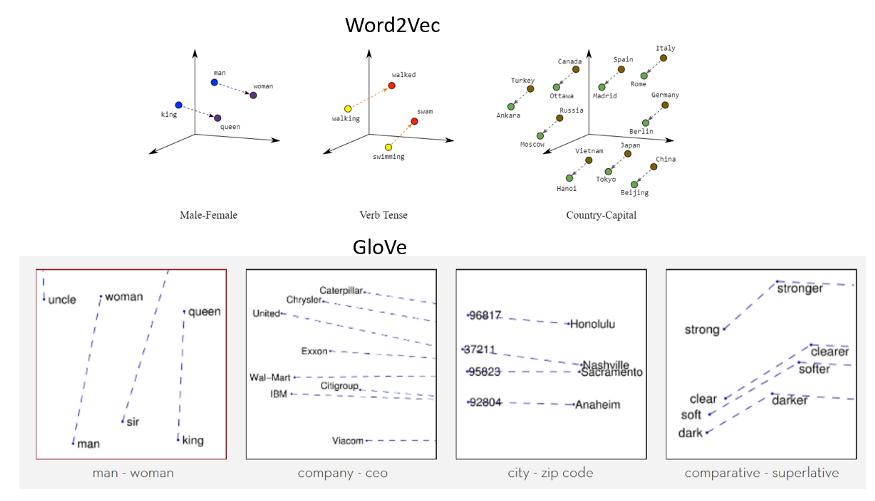
semantic relationships represented by Word2Vec and GloVe
A natural next step in the field was the development of sentence embeddings, or being able to extract meaning from a sequence of words. Early methods include:
In 2017, Arora et. al proposed SIF, or Smooth Inverse Frequency, a weighting scheme to improve performance of sentence embeddings. When encoding a sentence, it is important to identify which words in the sentence are more significant. For example, if calculating the embedding of the sentence “who was Mozart?” the word “was” doesn’t add much meaning; looking for sentences or documents relating to the word “was” will not yield any useful results for the original question. It’s clear that “Mozart” holds the most meaning in the question from a human standpoint, but how do you program a machine to identify that? SIF operates under the assumption that the most important words tend to also be used less frequently. If you counted all the words in Wikipedia, the word “was” would most likely appear much more frequently than in “Mozart”. Weights of a word w are computed by a/(a + p(w)) where a is a parameter and p(w) is the word frequency of w, which can be estimated by scraping a large corpus.* The hyperparameter *a adjusts which words are quantitatively “common” and “uncommon.” Here is the formal algorithm:

Arora et. al found that despite its simplicity, SIF worked surprisingly well on semantic text similarity (STS), entailment, and sentiment tasks. STS tasks involve scoring pairs of sentences from 0-5 based on how similar their meanings are, which are then checked against a golden standard of human generated scores. For example, “The bird is bathing in the sink” and “Birdie is washing itself in the water basin” should receive a 5. Entailment tasks involve identifying if one sentence entails that another one is true. For example, if you read the sentence “There is a soccer game with multiple males playing,” you could infer that the sentence “Several men are playing a sport” is true. Thus the first sentence, commonly referred to as the text entails the following, also known as the hypothesis.
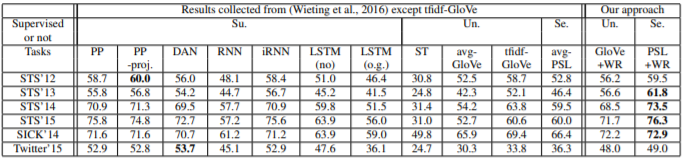

Tables detailing SIF performance on various semantic tasks. “GloVe + WR”, “PSL + WR”, and “Ours” correspond to SIF systems.
Due to its effectiveness and simplicity, SIF is an incredibly practical method of embedding sentences for commercial or enterprise products that rely on both accurate and fast results while consuming low amounts of resources.
The original code corresponding to the paper describing SIF is implemented in Python, which by design has a Global Interpreter Lock (GIL), a mutex that prevents multi threaded processes from utilizing multiple cores of a processor. We hosted our Cython implementation of the SIF embedding model on a cloud service, which provided us with multiple cores of processing power. However, the GIL meant that we could not make use of the full processing power we were paying for.
GoLang however, has no such restrictions and also provides built-in structures for concurrency through the form of Goroutines, a form of very lightweight threads. They are organized by channels, which allow goroutines to either block on awaiting input or signal that they have completed.
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
for i := 0; i < 4; i++ {
go worker(jobs, results)
}
for i := 0; i < 100; i++ {
jobs <- i
}
close(jobs)
for j := 0; j < 100; j++ {
fmt.Println(<-results)
}
}
func worker(jobs <-chan int, results chan<- int) {
for n := range jobs {
results <- fib(n)
}
}
func fib(n int) int {
if n <= 1 {
return n
}
return fib(n-1) + fib(n-2)
}
Basic architecture of a worker pool using goroutines
It is important to note that this structure does not enforce the order in which workers complete their jobs or the order in which their results are sent to the results channel. Executing this code won’t necessarily return the fibonacci numbers in their correct order.
Our API allowed for clients to send multiple sentences at a time to be encoded by the SIF, often many at a time, and implementing the SIF in Golang allowed us to leverage powerful concurrency to speed up our calculations. My first iteration of the SIF server used Golang’s http package to host the model on an HTTP 1.0 server. I compared it with our old system, as well as the original Python implementation. I used three different independent variables to benchmark how the performance scaled up: total words per ‘sentence’ to be embedded, total number of calls with fixed number of concurrent requests, and number of concurrent requests with fixed total number of calls. These benchmarks were made using Apache Benchmark, a software that allows you to make many concurrent requests to a server and reports significant timing data.
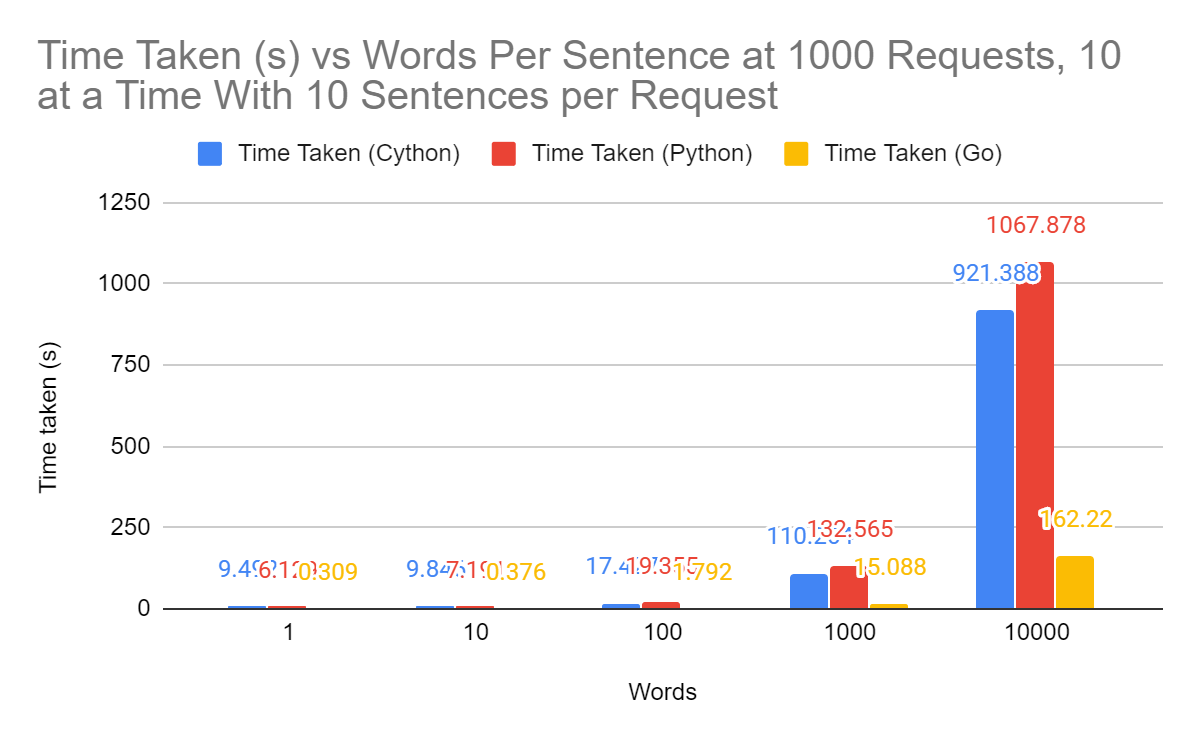
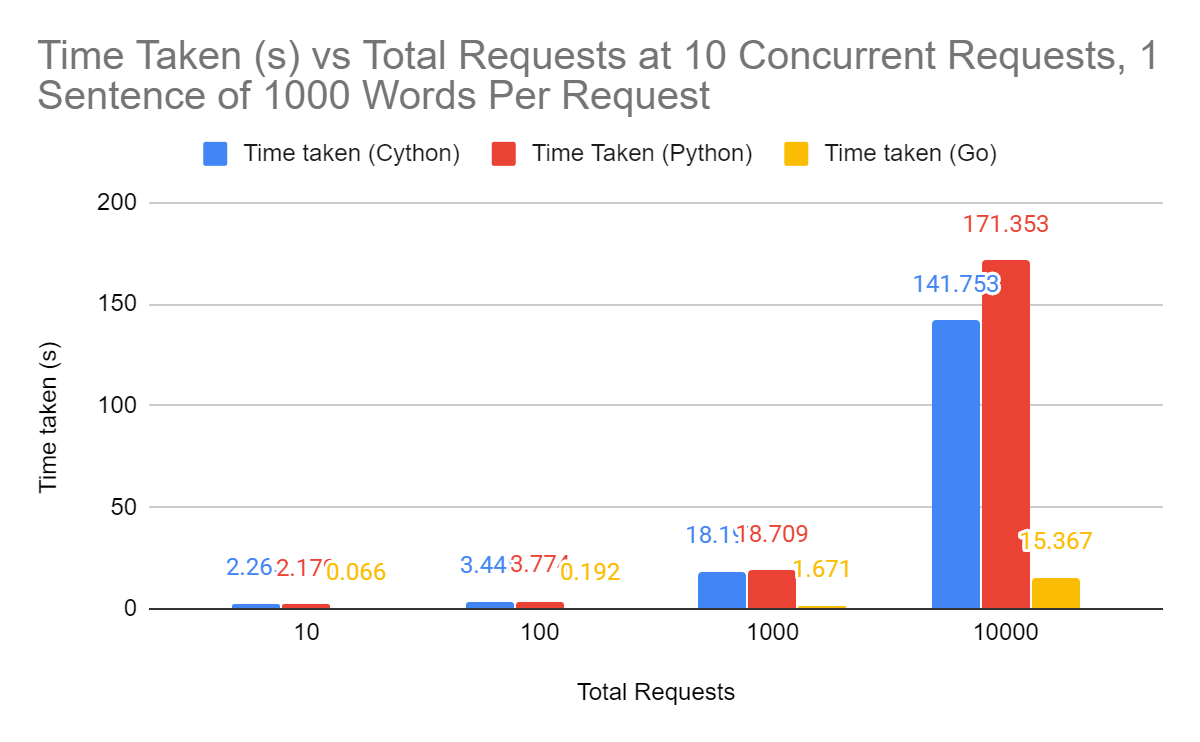
The results were impressive, to say the least. At a sentence level, around 10-100 words, the new implementation outperforms the old by up to 30x and at a document level, around 1000-10000+ words, it is still 10x** **faster in almost every scenario. The improved speed for sentence level embeddings is really useful, since it means that we can embed at lower levels of granularity much more easily. For example, if you were searching “who was Mozart” and only had embeddings for each document, your system might flag a document about Joseph Haydn, friend and mentor of Mozart, as relevant. As you descend levels of granularity of embeddings however, you can much more easily locate relevant information about your query. Perhaps it allows you to find a paragraph detailing their time in Vienna together, or a specific sentence about the pieces of music they worked on together.
I found that Go works incredibly well for creating a web service capable of handling many concurrent requests efficiently. However, Go’s build in functionality does have a significant limitation of restricting HTTP requests to sizes of 1MB or less, which was not ideal for our use cases where we had to embed large amounts of text in a single request. For example, a legal company looking to process Google’s 2019 environmental and sustainability report would need about 11 MB of payload. Or a stressed-out undergraduate trying to find tips in Cracking the Coding Interview would require around 90 MB of allowance. Additionally, every HTTP request requires a new connection to be made between the server and client, which adds a significant amount of overhead to our typical use case which often requires embedding many documents at once and sending many requests.
Developed by Google, gRPC is an open source Remote Procedure Call framework and is what I turned to in order to hopefully remove the size limit and connection overhead problems with Go’s http package. gRPC processes payloads from requests using buffers, so it removes the 1MB size cap on requests. It also maintains connections between individual clients, so a single user can make multiple requests without having to create a connection more than once. It has its own Interface Definition Language called protocol buffers that also serve as a mechanism for serializing structured data and uses HTTP/2 to transport data. gRPC services are defined in .proto files:
syntax = "proto3"
option go_package = “greeter”
package main
// The greeter service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
You can then use the protoc command to compile your service into any of gRPC’s supported languages.
// Code generated by protoc-gen-go. DO NOT EDIT.
// versions:
// protoc-gen-go v1.23.0
// protoc v3.6.1
// source: greeter.proto
package greeter
import (
proto "github.com/golang/protobuf/proto"
protoreflect "google.golang.org/protobuf/reflect/protoreflect"
protoimpl "google.golang.org/protobuf/runtime/protoimpl"
reflect "reflect"
sync "sync"
)
const (
// Verify that this generated code is sufficiently up-to-date.
_ = protoimpl.EnforceVersion(20 - protoimpl.MinVersion)
// Verify that runtime/protoimpl is sufficiently up-to-date.
_ = protoimpl.EnforceVersion(protoimpl.MaxVersion - 20)
)
// This is a compile-time assertion that a sufficiently up-to-date version
// of the legacy proto package is being used.
const _ = proto.ProtoPackageIsVersion4
// The request message containing the user's name.
type HelloRequest struct {
state protoimpl.MessageState
sizeCache protoimpl.SizeCache
unknownFields protoimpl.UnknownFields
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
}
//... excess code has been left out
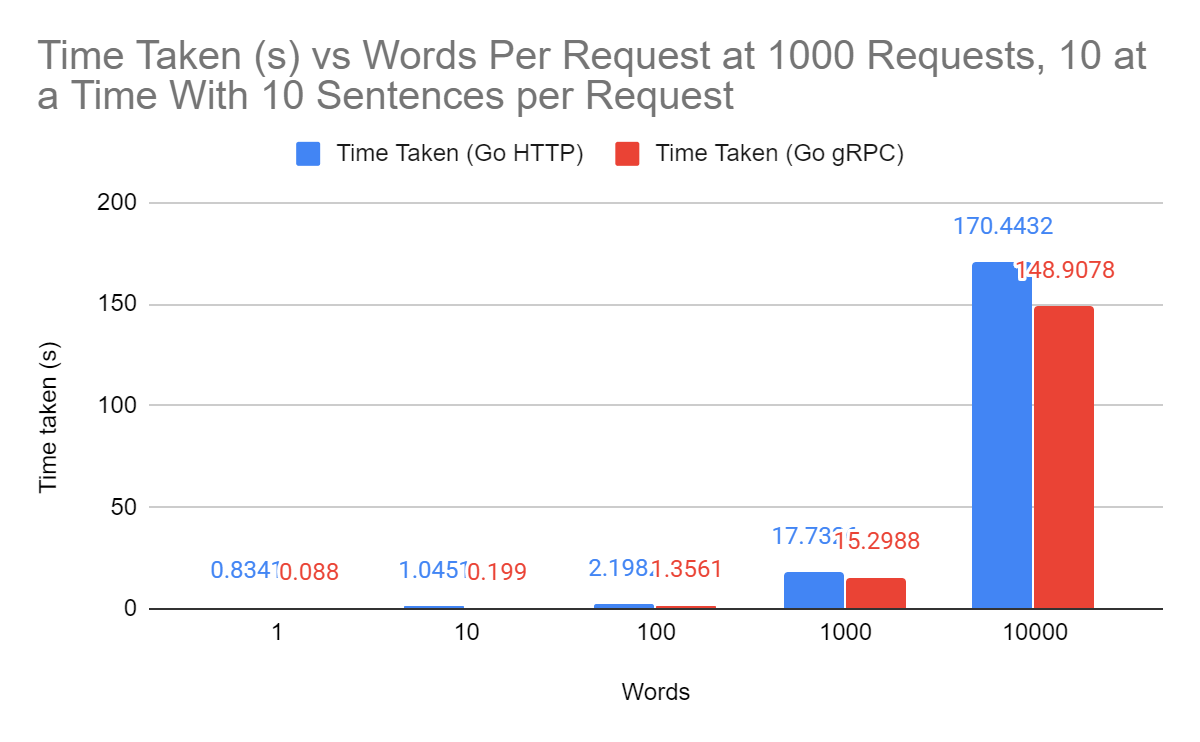
Due to how gRPC buffers data being received and sent, we no longer had to worry about size limits on requests to our server. gRPC servers also have a very helpful feature in that connections between client and server are maintained across multiple requests, whereas with HTTP requests, a new connection has to be established for every POST. As a result, I saw more improvements in performance as this overhead was removed from the new system:
The largest improvements are seen when requests have very small payloads, so the majority of time is spent on overhead from connecting to the server. However, once you get to larger payloads, the times converge to become about equal.
5. Post-Processing Improvements
A coworker sent me this paper about post-processing word vectors in order to improve their representation of meaning. The algorithm essentially takes a list of pre-computed word vectors and performs principal component analysis on them, and then removes the top N components from every vector via Gram-Schmidt. Here is their formal algorithm:

Python’s Numpy and sklearn packages have all the built-in tools needed to implement this algorithm, which you can find the code for here:
import numpy as np
from sklearn.decomposition import PCA
import argparse
parser = argparse.ArgumentParser(description='postprocess word embeddings')
parser.add_argument("file", help="file containing embeddings to be processed")
args = parser.parse_args()
N = 2
embedding_file = args.file
embs = []
#map indexes of word vectors in matrix to their corresponding words
idx_to_word = dict()
dimension = 0
#append each vector to a 2-D matrix and calculate average vector
with open(embedding_file, 'rb') as f:
first_line = []
for line in f:
first_line = line.rstrip().split()
dimension = len(first_line) - 1
if dimension < 100 :
continue
print("dimension: ", dimension)
break
avg_vec = [0] * dimension
vocab_size = 0
word = str(first_line[0].decode("utf-8"))
word = word.split("_")[0]
# print(word)
idx_to_word[vocab_size] = word
vec = [float(x) for x in first_line[1:]]
avg_vec = [vec[i] + avg_vec[i] for i in range(len(vec))]
vocab_size += 1
embs.append(vec)
for line in f:
line = line.rstrip().split()
word = str(line[0].decode("utf-8"))
word = word.split("_")[0]
idx_to_word[vocab_size] = word
vec = [float(x) for x in line[1:]]
avg_vec = [vec[i] + avg_vec[i] for i in range(len(vec))]
vocab_size += 1
embs.append(vec)
avg_vec = [x / vocab_size for x in avg_vec]
# convert to numpy array
embs = np.array(embs)
#subtract average vector from each vector
for i in range(len(embs)):
new_vec = [embs[i][j] - avg_vec[j] for j in range(len(avg_vec))]
embs[i] = np.array(new_vec)
#principal component analysis using sklearn
pca = PCA()
pca.fit(embs)
#remove the top N components from each vector
for i in range(len(embs)):
preprocess_sum = [0] * dimension
for j in range(N):
princip = np.array(pca.components_[j])
preprocess = princip.dot(embs[i])
preprocess_vec = [princip[k] * preprocess for k in range(len(princip))]
preprocess_sum = [preprocess_sum[k] + preprocess_vec[k] for k in range(len(preprocess_sum))]
embs[i] = np.array([embs[i][j] - preprocess_sum[j] for j in range(len(preprocess_sum))])
file = open("postprocessed_embeddings.txt", "w+", encoding="utf-8")
#write back new word vector file
idx = 0
for vec in embs:
file.write(idx_to_word[idx])
file.write(" ")
for num in vec:
file.write(str(num))
file.write(" ")
file.write("\n")
idx+=1
file.close()
print("Wrote: ", len(embs), "word embeddings")
Using the new word embedding file, I saw meaningful improvements in semantic similarity tasks, similar to the results they found in their paper:
| Dataset | k | Original | Post-Processed Vectors |
| MSR Paraphrase | k = 1 | 76.43 | 78.34 |
| MS MARCO, 10000 | k = 1 | 18.2002 | 20.4 |
| MSR Paraphrase | k = 3 | 87.122 | 88.84 |
| MS MARCO, 10000 | k = 3 | 26.915 | 29.37 |
| MSR Paraphrase | k = 5 | 89.37944567 | 90.92 |
| MS MARCO, 10000 | k = 5 | 33.05634374 | 36.2 |
I benchmarked the system on semantic text similarities tests using the MSR Paraphrase dataset, as well as the first 10000 entries of the MS MARCO dataset using p@k with k = 1, 3, and 5. These tasks involved identifying a sentence from a large pool of candidates as being semantically equivalent to another. p@k testing introduces some leeway into the testing, where the program chooses the top K candidates from the pool as potential matches instead of only getting one attempt at the correct answer. This kind of testing is more representative of a search engine, where you care not only about getting the single best result, but also a reasonable amount of relevant information.
The post-processed vectors outperformed the original in every case. I also benchmarked our system using a word frequency file generated by fellow intern Connie Xu using a June snapshot of all of Wikipedia. It had a far more comprehensive vocabulary than our current word frequency file, with over 50x as many entries, but performance results were inconclusive. The results do indicate, however, that post-processed word vectors also increase performance of sentence embedding systems.
6. Productionalizing With Docker
After finishing the code for our new SIF, my final step was to prepare it for production, which meant an inevitable encounter with Docker. Here is my Dockerfile, which I got from this tutorial:
# Start from the latest golang base image
FROM golang:latest
# Add Maintainer Info
LABEL maintainer="Daniel Ye <daniel.ye@nlmatics.com>"
# Set the Current Working Directory inside the container
WORKDIR /app
# Copy go mod and sum files
COPY go.mod go.sum ./
# Download all dependencies. Dependencies will be cached if the go.mod and go.sum files are not changed
RUN go mod download
# Copy the source from the current directory to the Working Directory inside the container
COPY . .
# Build the Go app
RUN go build -o main .
# Expose port 8080 to the outside world
EXPOSE 8080
# Command to run the executable
CMD ["./main"]
Most components are fairly self-explanatory. It does require that you use Go modules to manage your dependencies, which you can read about here. The steps I took to compile my code into a Docker image were as follows:
-
Create a go mod file in the root directory of your Golang project using go mod init
. Your project name can be anything you want, it does not have to correspond to any file or package names, although it probably should. -
Populate your go mod file with dependencies using go build. This will automatically detect the packages used by your project, and write them to your go mod file
-
Create a Dockerfile in the root directory of your project
-
Build your image using docker build -t
. Include the period! -
Run your project with docker run -d -p 8080:8080
Improving the SIF implementation was a really interesting project. There were a lot of fun challenges involved like solving the ordering of goroutines and dealing with concurrent writes to map. It was incredibly satisfying to run my own benchmarks and see quantitative improvements in performance go as high as 30x the original speed. Of course, more improvements can still be made. This paper details how SIF embeddings of documents can be improved by producing and then combining topic vectors. Other models for embedding sentences such as Universal Sentence Encoder or Sentence-BERT have been developed in recent years as well and are able to outperform SIF in certain categories of NLP tasks.