
Optimizing Transformer Q&A Models for Naturalistic Search
Optimizing Transformer Q&A Models for Naturalistic Search
By Batya Stein
Introduction
Have you ever wondered what the most popular pizza topping in America is? To find out, you might Google “what is the most popular pizza topping in America?”. If you’re feeling lazy, maybe you’d leave out the question mark, or drop the question format altogether, and go with a simple “most popular pizza topping in America”.
 This probably seems like an excessive amount of thought to put into a Google search query, especially since all the above prompts return the same information. (Pepperoni, for the curious.) With or without the question word and question mark, you can intuitively recognize that all these formulations are essentially asking for the same answer.
This probably seems like an excessive amount of thought to put into a Google search query, especially since all the above prompts return the same information. (Pepperoni, for the curious.) With or without the question word and question mark, you can intuitively recognize that all these formulations are essentially asking for the same answer.
However, imagine that you wanted to train a machine learning model to complete a similar exercise. If you fed your model background material on America’s pizza-eating habits, and then asked it some variation of the topping question, you’d like it to identify the answer “pepperoni” within the text. Models are usually trained for this type of question-answering task using reading comprehension datasets, like the Stanford Question Answering Dataset (SQuAD). SQuAD’s examples consist of context paragraphs from Wikipedia, and questions which either have answers located within the context paragraphs, or are unanswerable. Each question is written as a full sentence, complete with a question mark at the end. Nearly all questions contain a question word (“who”, “what”, “where”, etc.).
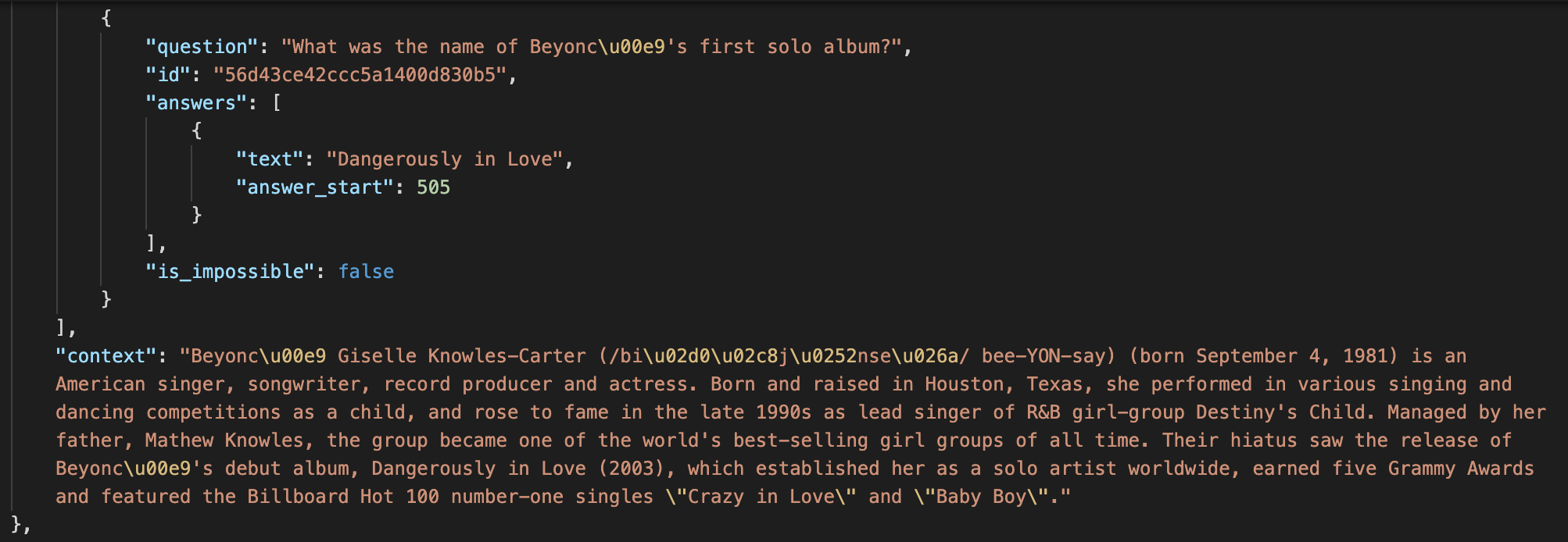
Example of SQuAD question and context paragraph
Given that a model trained on SQuAD has only been exposed to prompts in the form of questions, the specific way a user words their query takes on new importance. Would a model trained only on questions be able to process phrases and match them to answers with the same accuracy as it can questions? In other words, which characteristics are most necessary for a prompt to be accurately understood by a SQuAD-trained model? Though it may seem obvious to you and me that “what is the most popular topping?” is basically synonymous with “the most popular topping”, it is not clear that the same would be apparent to a SQuAD-trained model.
Experiment Motivation
As an intern at NLMatics this summer, I ran a series of experiments using transformer-based question-answering models and the SQuAD 2.0 dataset to explore how the wording of a dataset’s questions impacts a model’s accuracy. My goal was to see if:
-
a model trained only on question-answer pairs (e.g. the standard SQuAD dataset) would give accurate results when evaluated on phrase-answer pairs, and
-
If a model trained on phrase-answer pairs could achieve the same performance scores (F1 and exact match) when asked to predict answers for phrases, as a model trained on normal SQuAD achieves when asked to predict answers to questions.
I also trained models on different permutations of the phrase and question datasets - phrases with question marks, and questions without question marks - to isolate the characteristics that make a question answering model effective. Is it the presence of a question mark, or of a question word, or simply the keywords of a phrase?
The results of these experiments are relevant for any system where a user directly queries a text using a question-answering model. The designer of the system doesn’t necessarily have control over the questions users ask, or a way of knowing if they will choose to input questions (ex. “where is the building?”) or phrases (ex. “building location”). If a model could be trained for accuracy in phrase answering tasks without a significant decrease in accuracy on question answering tasks, users would be able to input a much broader range of questions, without the designer having to worry about precise wording.
Question to Phrase Conversion
In order to create a dataset of phrases directly comparable to a question dataset, I decided to reformat the SQuAD 2.0 dataset into phrases. (Google Natural Questions, another large reading comprehension dataset, has some examples that are already written as phrases and some written as questions, but the variability makes it less useful for direct comparisons.) My goal when converting the questions was to create phrases that sounded like something natural a user might type into a search engine, so that the training data would be similar to what would be seen in a real use case.
To this end, I wrote a python script to process SQuAD that, besides deleting question words, changed tenses when necessary, moved verbs after subjects, and reordered the clauses of complex questions. I used the spaCy NLP library for part-of-speech tagging and dependency parsing (ex. identifying the subject of a sentence), and the pattern library for verb conjugation. The code had rules for handling questions based on the question words they began with, and a separate rule for handling questions with more complex structures.
Some example outputs from my phrase conversion code:
| Original Question | New Phrase | Comment |
|---|---|---|
| “On what date did Henry Kissinger negotiate an Israeli troop withdrawal from the Sinai Peninsula?” | “date Henry Kissinger negotiated an Israeli troop withdrawal from Sinai Peninsula on” | To create a natural sounding phrase after deleting “did” from questions, I used the pattern library’s verb conjugation function to change remaining verbs to past tense |
| “Atticus Finch’s integrity has become a model for which job?” | “job Atticus Finch’s integrity has become a model for” | For examples where question words appeared mid-sentence (instead of as the first word), I split questions at the question word and moved the first clause to the back |
| “Where would present day Joara be?” | “present day Joara would be” | When a phrase wouldn’t make sense without an auxiliary verb like “would”, “could”, “can”, etc., I used spaCy to identify the question’s subject, and moved the auxiliary verb behind it (otherwise, I deleted unnecessary auxiliary verbs such as “are” or “is”) |
Model Training
To figure out which characteristics of a question were most important, I trained four ALBERT models on four different datasets. ALBERT is a light variation of the BERT transformer model with fewer parameters for an even quicker training time than BERT. (See the original paper on BERT here, with a helpful explanation here and a general overview of transformer architecture here.)
The four datasets I used were:
- Normal SQuAD (2.0) dataset - a baseline for comparison

- SQuAD converted to phrases - can the model match phrases to answers effectively since they are more open ended than questions?

- SQuAD questions without question marks - how important is question mark in getting the model to recognize a question?

- SQuAD converted to phrases, with question marks appended - does the addition of a question mark compensate for the lack of a question structure?

The ALBERT XL model that I used came from Huggingface’s transformer library, and for training I used Huggingface’s run_squad.py script. I used wandb, a web-based training visualization library, to monitor metrics throughout my trainings. The trainings were run on Amazon EC2 p2.8xl instances (8 NVIDIA K80 GPUs).
SQuAD Metrics
The official metrics for evaluating a SQuAD trained model are calculated in the evaluation script linked on SQuAD’s website. The two main metrics are “exact” and “F1”. Exact” returns the percentage of examples that the model predicted correct answers for out of all test examples. “F1” is an accuracy measure combining precision (number of true positives over total predicted positives) and recall (number of true positives over everything that should have been identified as positive). To calculate F1 scores for SQuAD, for each example in the evaluation set, precision is the number of overlapping words between the correct and predicted answers, divided by the number of words in the predicted answer. Recall is the number of overlapping words divided by the number of words in the correct answer.
The metrics return F1 and exact scores over all the evaluation set examples, as well as F1 and exact scores over the subset of evaluation examples that have answers, (“HasAns”) and over the subset of examples that are impossible to answer (“NoAns”).
Results and Discussion
To analyze the results of my 4 model trainings, I first compared the performances of each model evaluated on its own dev set (I used dev sets for evaluations since SQuAD’s test set is not publicly available). In other words, after training, how accurately would each model perform on unseen data formatted the same way as its training data?
(For consistency, results shown below are evaluated at the 7000th training step, towards the end of the 2nd epoch. The exception is the F1 score chart, which spans from beginning to end of training.)
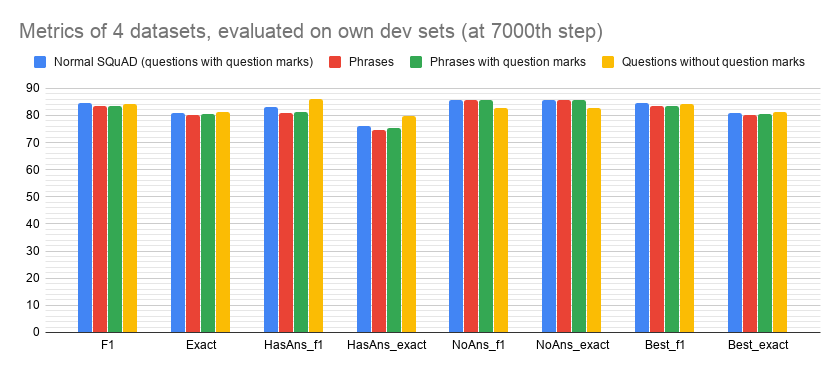
Metrics of 4 datasets, evaluated on their own dev sets at 7000th step
| Normal SQuAD (questions with question marks) | Phrases | Phrases with question marks | Questions without question marks | |
|---|---|---|---|---|
| F1 | 84.42 | 83.3 | 83.59 | 84.23 |
| Exact | 80.86 | 80.27 | 80.67 | 81.24 |
| HasAns_f1 | 83.2 | 80.77 | 81.36 | 85.9 |
| HasAns_exact | 76.06 | 74.7 | 75.52 | 79.91 |
| NoAns_f1 | 85.63 | 85.82 | 85.8 | 82.57 |
| NoAns_exact | 85.63 | 85.82 | 85.8 | 82.57 |
| Best_f1 | 84.42 | 83.3 | 83.59 | 84.23 |
| Best_exact | 80.86 | 80.27 | 80.67 | 81.24 |
F1 scores for all models throughout training
| Step | SQuAD | Phrases | Phrases with q marks | Q’s without q marks |
|---|---|---|---|---|
| 500 | 64.98 | 63.54 | 68.50 | 72.47 |
| 1000 | 77.08 | 76.08 | 77.05 | 77.86 |
| 1500 | 77.75 | 77.01 | 77.40 | 78.93 |
| 2000 | 80.52 | 79.35 | 79.44 | 80.93 |
| 2500 | 80.82 | 79.50 | 79.05 | 81.19 |
| 3000 | 81.81 | 79.05 | 80.62 | 82.22 |
| 3500 | 80.91 | 80.36 | 80.71 | 80.93 |
| 4000 | 82.28 | 80.37 | 80.95 | 83.07 |
| 4500 | 83.09 | 81.01 | 81.15 | 82.70 |
| 5000 | 83.06 | 81.65 | 82.47 | 83.59 |
| 5500 | 83.84 | 82.85 | 82.50 | 84.09 |
| 6000 | 84.27 | 82.48 | 83.20 | 84.46 |
| 6500 | 84.46 | 82.02 | 83.38 | 84.44 |
| 7000 | 84.42 | 83.30 | 83.59 | 84.23 |
| 7500 | 84.80 | 83.01 | 83.54 | 84.83 |
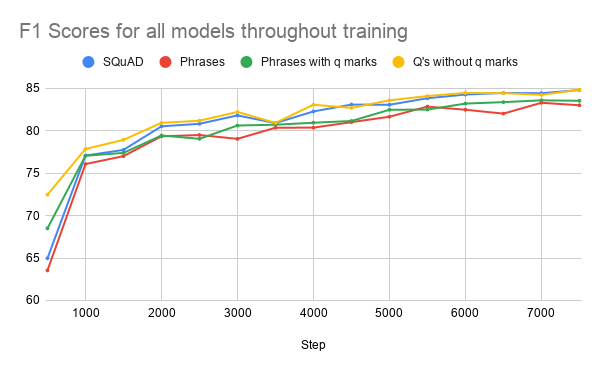
As expected, the standard SQuAD-trained model has high metrics across the board and high F1 scores throughout training, since its examples have the most context for the model to pick up on (question format and question marks). Interestingly, the SQuAD without question marks model does better than the standard SQuAD model for the “HasAns” metrics (HasAns F1 of 85.90 vs 83.20), and notably worse for the “NoAns” (NoAns F1 of 82.57 vs 85.63)- I am not sure exactly what to conclude from this (it may not be a conclusive trend, as the bar graph only represents one checkpoint from training). Overall though, throughout training, the F1 scores of the SQuAD without question marks model were equal to, or higher than, the standard SQuAD F1’s, showing that the inclusion or exclusion of question marks seems relatively insignificant for achieving accuracy.
The phrase-trained model metrics are equal to, or 1-3 points lower than the standard SQuAD metrics, and its F1 scores throughout training are lower overall but not to a super significant extent. This answers one of my main beginning questions, indicating that while there is some increased accuracy associated with the additional context of a question structure, a model trained on phrase-answer pairs does not show a significant decrease in accuracy.
Adding question marks to phrases does yield slightly better F1 scores throughout training (see graph above). A possible interpretation of this trend is that all the contextual question information is present, question marks are essentially negligible, but with less information presented, as in phrases, the question mark does help increase accuracy.
For the second part of my analysis, I evaluated each of the models on the standard SQuAD dev set, and the standard SQuAD trained model on the phrase dev set. (All results evaluated at the 7000th step, as above). Through these evaluations I hoped to see how well a model trained on a modified dataset could perform on a differently formatted question.
Question-trained model evaluated on questions vs on phrases
| eval on phrase dev set | eval on question dev set | |
|---|---|---|
| F1 | 83.3 | 81.12 |
| Exact | 80.27 | 77.83 |
| HasAns_f1 | 80.77 | 80.64 |
| HasAns_exact | 74.7 | 74.06 |
| NoAns_f1 | 85.82 | 81.6 |
| NoAns_exact | 85.82 | 81.6 |
| Best_f1 | 83.3 | 81.12 |
| Best_exact | 80.27 | 77.83 |
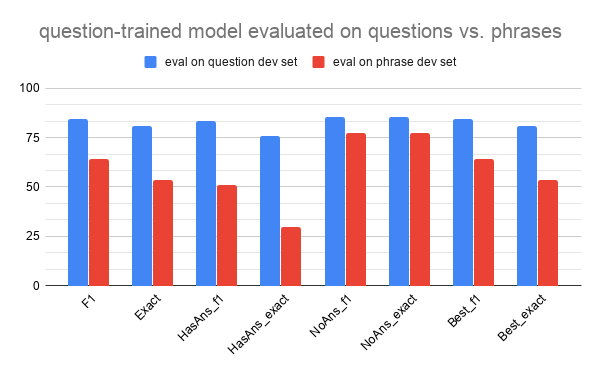
Notably, a standard SQuAD-trained model performs really poorly when evaluated on phrases, as shown in the charts above. Its F1 score drops from 84.42 (evaluated on questions) to 64.11 (evaluated on phrases), and its HasAnsF1 score drops from 83.20 to 50.96. Practically, this proves the necessity of training models that are better equipped to deal with phrases. On a theoretical level, this indicates that the model comes to rely on question words/ structure for context when trained on questions, and therefore it can’t process questions accurately without them. (That’s not to say that question words are inherently necessary for achieving accuracy in training - see phrase-trained model metrics above - rather, once a model is trained on questions, it will become reliant on question characteristics).
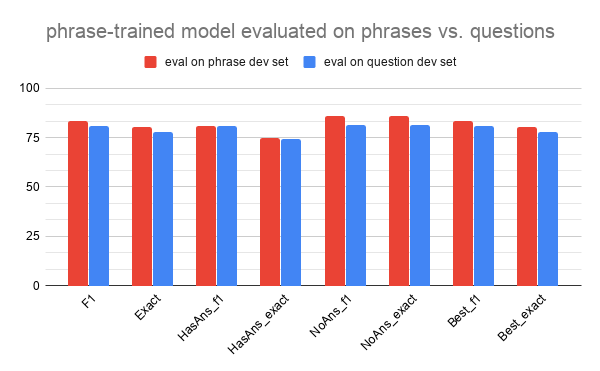
On the other hand, as shown in the charts below, a model trained on phrases performs almost as accurately on standard questions as it does on its own dev set - it’s well adapted to inputs of both phrases and questions. It does slightly better on the phrase evaluation, seemingly because the model learns weights corresponding to the format of its training data, but since here the second dev set (questions) introduces new information instead of taking away expected context, the extra input barely hurts. In other words, the phrase-trained model is more robust for a general set of inputs than a question-based model because it was forced to learn from less context per data point originally. However, it performs slightly less accurately on questions as compared to a question-trained model evaluated on questions (or as compared to its own performance on phrases).
Phrase trained model evaluated on phrases vs. questions
| eval on phrase dev set | eval on question dev set | |
|---|---|---|
| F1 | 83.3 | 81.12 |
| Exact | 80.27 | 77.83 |
| HasAns_f1 | 80.77 | 80.64 |
| HasAns_exact | 74.7 | 74.06 |
| NoAns_f1 | 85.82 | 81.6 |
| NoAns_exact | 85.82 | 81.6 |
| Best_f1 | 83.3 | 81.12 |
| Best_exact | 80.27 | 77.83 |
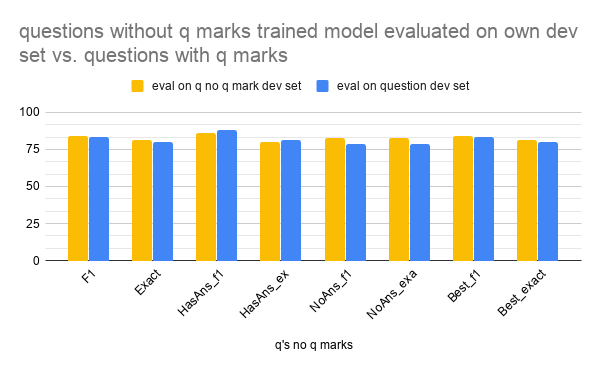
One other interesting result came from the model trained on questions without question marks, shown in the charts below. When evaluated on questions with question marks (i.e. normal SQuAD) the metrics were slightly better than on its own dev set for the “HasAns” metrics, but slightly worse for the “NoAns”. I would guess this is because if the model isn’t exposed to question marks during training, but then is given a question with a question mark, it will be more likely to assume that the question is answerable given the extra input, which leads to increased accuracy if the question actually has an answer, but decreased accuracy when the question is impossible.
Questions without question mark model evaluated on own dev set vs. normal SQuAD
| eval on q no q mark dev set | eval on question dev set | |
|---|---|---|
| F1 | 84.23 | 83.24 |
| Exact | 81.24 | 80.12 |
| HasAns_f1 | 85.9 | 87.76 |
| HasAns_exact | 79.91 | 81.51 |
| NoAns_f1 | 82.57 | 78.73 |
| NoAns_exact | 82.57 | 78.73 |
| Best_f1 | 84.23 | 83.25 |
| Best_exact | 81.24 | 80.13 |
In conclusion, it seems that BERT transformer models begin to recognize and expect specific characteristics from their training data. This affects the results when a model is evaluated on data formatted differently from its original training set, but to a much less dramatic extent if information is being added rather than taken away. On the other hand, the initial dataset a model is trained on doesn’t affect accuracy as much as you might think it would - a model trained on phrases will be within a few points of a question-trained model’s accuracy, and adding or taking away question marks makes a mostly negligible difference. Running these experiments was cool because I was able to get a better feel for how a model actually adapts to a dataset when training on it. I also think the results I found can be practically pretty helpful for anyone designing a question-answering system and wondering what types of input would be most effective.
Further Developments
Each model presented here was only trained once. To run this as a full experiment, ensuring that the results are significant, you would have to set random seeds and run each training about ten times to get standard deviations.
Additionally, there are a few ways to build on this project that I think could be interesting. You could train an ALBERT model twice, on normal SQuAD and then on SQuAD converted to phrases, to see if it achieves better results on both questions and phrases. However, training a model twice on the same data might lead to overfitting on SQuAD. An alternative would be to train a model using MAML, Model Agnostic Meta Learning, which allows a model to learn multiple different tasks, treating questions and phrases as two separate tasks. It would also be interesting to train a model on the full Google Natural Questions dataset, which is already a mixture of questions and phrases, and evaluate it just with a question dataset and just with a phrase dataset to see how the mixture and larger dataset size affect the results.
Thank you to my supervisor, Sonia Joseph, who initially proposed this idea to me, helped along the way, and introduced me to MAML.